a. Llaves primarias
b. Reglas de integridad
c. Llaves foráneas e integridad
referencial
4. Diseño de Bases de Datos
a. Facilidad de acceso a la
información
b. Facilidad de extraer la
información
c. Definición de Datos
i. Tablas base
ii. Vistas
iii. Criterios para la creación de
Ãndices
i. Consultas Simples
ii. Consultas agregadas
iii. Actualizaciones
e. Diccionario de
Datos (ImportantÃsimo)
5. El
lenguaje SQL
a. Create
a. Permisos de acceso
b. Transacciones
Identificación de los
recursos
HUMANOS
Tutor Docente del Pre – Palestina
Ejecutor: Estudiante de TecnologÃa en
Computación e Informática del
Programa
Regional de Enseñanza PalestinaPersonal Docente del Ãrea de
InformáticaPersonal especializado en Bases de Datos
Personal especializado en Programación
MATERIALES
Computadora
Internet
Libros de Bases de Datos
Libros de Oracle
Programa Visual Studio
Programa Windows
XPHojas A4
Impresoras Multifunción
Un Proveedor de Internet
Un cableado estructurado
Una red local
Computadoras Pentium
IV

LA IMPORTANCIA DE LAS BASES DE DATOS
La explosión de nuevas tecnologÃas
que empezó con la introducción del PC y
la llegada del Internet ha brindado al
marketing
opciones y herramientas
que son explotadas con gran intensidad en la actualidad. Una de
ellas es la utilización de instrumentos de
información en la generación de
bases de
datos, o también llamado "database marketing",
que es simplemente el uso de bases de datos
(información) enfocados al cliente.
Conocer a los clientes y saber
sus preferencias es un recurso vital en el desarrollo de
productos y
estrategias de
ventas.
Poder conocer
con exactitud los datos básicos de
segmentación del cliente (sexo, edad,
preferencias básicas etc.) y tal vez poder ir
más allá en el
conocimiento (preferencias personales, aficiones, gustos
básicos, marcas
preferidas) resultan recursos muy
valiosos para las empresas.Â
Los datos recogidos de los clientes, formarán
bases de clientes, de usuarios registrados y de posibles
compradores, quienes serán susceptibles de recibir
información actualizada de productos y servicios
ofrecidos. Â
En éste entorno, la recopilación de
bases de datos servirá a las empresas
para:Â Â
Mantener comunicación constante con los
clientes (mail, teléfono, correo etc.)Personalizar la atención a los usuarios.
Generar estrategias de publicidad.
Utilizar segmentos especÃficos de clientes
para colocar productos especÃficos y
asà llegar de manera directa al comprador o
usuario.Comentar las novedades, promociones y noticias
relacionadas con el negocio y en algunas ocasiones con el
sector al que se dedica la
empresa.
 En fin, mantener una base de datos,
resulta un instrumento de información muy valioso y
que puede ser aprovechado efectivamente en la
generación de ventas y utilidades. Tener y
administrar bases de datos con clientes, implica un problema de
información, el cual genera consideraciones de
almacenamiento,
seguridad y uso.
Ante estos problemas
aparecen procesos y
tecnologÃas nuevas que buscan suplir las necesidades
de manejo de información en las empresas. Nacen
asà conceptos que serán aplicados al
manejo de grandes volúmenes de
información como por
ejemplo:Â Â
Datawarehouse: Es simplemente el término
para "almacenaje de volúmenes de
información". Consiste prácticamente
en la utilización de sistemas de
almacenamiento en medios
electrónicos o magnéticos bajo un
ambiente de
seguridad de la información
recopilada.Â
Fullfilment: Básicamente son
estrategias de fidelización, mediante
comunicación constante y
retroalimentación buscando la mayor comodidad de
comunicación al cliente y buscando mejorar niveles
de venta.
Datamining: Consiste en extraer
información de las bases de datos
existentes para aprovecharlas en fines
especÃficos. Es el proceso de
extracción de información significativa
de grandes bases de datos, información que revela
inteligencia
del negocio, a través de factores ocultos,
tendencias y correlaciones para permitir al usuario realizar
predicciones que resuelven problemas del negocio proporcionando
una ventaja competitiva. Las herramientas de datamining predicen
las nuevas perspectivas y pronostican la situación
futura de la empresa, esto
ayuda a los mismos a tomar decisiones de negocios pro
activamente.Â
 El uso de bases de datos podrÃa crea
algunos problemas, especialmente desde el punto de vista del
consumidor, como
por ejemplo:Â Â
Falta de seguridad: Es muy difÃcil
garantizar en la actualidad, completa seguridad en el manejo de
la información que recopilan las empresas y es
difÃcil estar 100% seguro de que los
datos entregados por el consumidor serán utilizados
únicamente para los fines en que se entregaron
dichos
datos.   Â
Confiabilidad: No siempre los datos recopilados son
totalmente confiables, muchas veces los usuarios por no
comprometer su integridad, utilizan datos inexactos y no son del
todo sinceros.
Éste es un problema tÃpico en los
Bancos, en
donde en algunas ocasiones se brinda información
inexacta acerca de niveles de ingresos, deudas
etc.
Ética: Un problema serio es el manejo de la
información por parte de los administradores de la
base de datos, a veces, las preferencias por productos
individuales y la información inexacta lleva al
consumidor a elegir productos de mala calidad y con
especificaciones que no son claras.
 Con respecto a lo contenido en una base de datos,
no existe un número de elementos minimamente
necesarios. Cada empresa debe realizar una auditoria rigurosa de
sus necesidades de información en
función de sus objetivos.Â
La mejor base de datos es aquella que por sus contenidos puede
aparentar más complejidad o
sofisticación en la información que
proporciona. Frecuentemente, una base de datos de aparente
simplicidad, pero con contenidos perfectamente adaptados los
objetivos relacionales, cumplirá su papel de apoyar
de forma discreta el conjunto de decisiones a tomar en la
estrategia
relacional. Â
No obstante, para lograr lo anterior, personalizar el
marketing y construir relaciones estrechas con los clientes, es
necesario apoyarse en tecnologÃas de
información, en sistemas que están
diseñadas para manejar grandes
volúmenes de datos y administrar la
información a través del proceso de
negocios.Â
Una de las tecnologÃas que satisface esta
necesidad es el CRM, un
software que
provee aplicaciones que integran marketing, ventas, e-commerce
(comercio
electrónico) y servicios de soporte al cliente para
la empresa.Â
El CRM es en sà una estrategia de negocios que
está plenamente orientado al
cliente.Â
Ahora bien, el CRM no es un nuevo concepto de marketing,
aunque está basado en tres aspectos de su
administración:
Orientado al cliente,
Marketing relacional
Base de datos de marketing
 Â
Â
Todas las organizaciones
tienen datos crÃticos.
Los Bancos almacenan información de cuentas.
Las bibliotecas almacenan información
acerca de los libros.Los hospitales almacenan información acerca
de los pacientes.
Las casas de remates almacenan información acerca
de los Ãtems a rematar y de los clientes que los
rematan
Todas las organizaciones deben crear y manipular datos tan
eficientemente como sea posible.
Considere retirar dinero de un
banco, sin un
sistema
informático.
Usted camina hasta la caja para retirar $100.000.
El cajero debe llamar "a la oficina
central" para comprobar el libro
mayor principal para estar seguro que hay suficientes fondos.
Si hay, ese libro mayor se debe actualizar a mano para
reflejar el retiro.¿Es esto eficiente para el banco o los
clientes?
Los datos de la organización deben
ser almacenados en forma confiable.
Los datos no pueden ser destruidos o perdidos.
Los datos no pueden ser inconsistentes.
Origen de Las Bases de Datos
Anterior a las Bases de datos, solo existÃa
una colección de Archivos
tradicionales.Su administración se realizaba a
través de cada programa que lo utilizaba.Los sistemas se desarrollaban absolutamente "Parcelados"
dentro de la misma organización.Cada "Parcela" generaba datos similares, lo que produce la
no deseada "Duplicidad"Cada "Parcela" actualizaba en sus ciclos los datos comunes
a la Organización, lo que produce la no deseada
"no-Integridad"
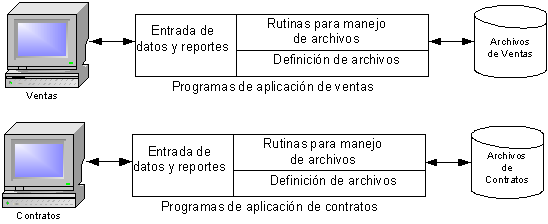
Usando archivos de datos tradicionales, las aplicaciones
deben acceder a los datos directamente.
Las aplicaciones deben estar enterados de la estructura
de archivo. Si
la estructura de archivo cambia, todos los programas que
tienen acceso a estos datos se deben también
modificar para reflejar los cambios.Las aplicaciones pueden tener que acceder datos que no
necesitan mientras buscan alguna pieza de datos.Una colección de programas de
aplicación que realizan servicios para el
usuario final, (Ej: producción de reportes.)Cada programa define y administra sus propios datos.
Ejemplo:Archivos Biblioteca
Considere una biblioteca que almacena
información de libros en archivos de texto. Los
tÃtulos se asignan en treinta caracteres, los
nombres del autor se asignan en veinte caracteres, y el
número de páginas se asigna en
cuatro caracteres.
Se delimita cada campo usando el carácter ` | '
. Por ejemplo, la estructura del archivo seria como sigue:
Title |Author |Page
Dr. Zhivago |Boris Pasternack | 540
Cada aplicación que accede a estos datos debe
conocer, que el titulo es leÃdo en string de 30
caracteres, el autor en string de 20 caracteres, y el
número de páginas del libro en
string de cuatro caracteres.
¿Que ocurre si …
al archivo de propietarios se decide
añadirle un campo que almacene un segundo
teléfono?Deseamos insertar al archivo de Biblioteca?
Hay Que…
Modificar las aplicaciones, incluso las que no utilizan
esos campos se pueden ver afectadas y tener que ser
modificadasMigrar los archivos al nuevo formato
El enfoque de Archivos

Los sistemas orientados hacia el proceso
Pone el énfasis en los tratamientos que reciben
los datos, los cuales se almacenan en Archivos
diseñados para una determinada
aplicación
Las aplicaciones se analizan e implantan con entera
independencia unas de otras, ylos datos no se suelen transferir entre ellas, sino que se
duplican siempre que los correspondientes proyectos los
necesitan.
LIMITACIONES CON EL ENFOQUE BASADO EN ARCHIVOS
Separación y aislamiento de datos
Cada programa maneja su propio conjunto de datos
Los usuarios de un programa pueden no estar enterados de
los datos potencialmente útiles llevados a cabo
por otros programas
Duplicación de datos
Mismos datos son mantenidos por diferentes programas
Espacio perdido y valores
potencialmente diversos y/o diferentes formatos para el mismo
dato.
Dependencia de datos
La estructura fÃsica y almacenamiento de los
archivos son definidos en el código de la
aplicación.Formatos de archivos incompatibles
las estructuras son dependientes del lenguaje
de programación de aplicaciones.
Proliferación de programas de
aplicación y consultas Pre-definidas
Los programas se escriben para satisfacer funciones
particulares.Cualquier nuevo requisito necesita un nuevo programa
No pueden almacenar reglas de Integridad
Dificultad para procesar consultas que no se realizan con
frecuencia
CONCEPTOS Y DEFINICIONES
Origen de Las Bases de Datos
Solución
La creación de un Software especializado que se
encargue de realizar la
ADMINISTRACION de los datos de que hacen uso los Software de
Aplicaciones…
SISTEMA ADMINISTRADOR DE
BASES DE DATOS
(DBMS: Data Base Managment System)
Un DBMS es una colección de
numerosas rutinas de software interrelacionadas, cada una de
las cuales es responsable de una tarea especÃfica
en relación a la administración y
organización de las bases de datos.El objetivo primordial de un sistema manejador base de
datos es proporcionar un entorno que sea a la vez conveniente
y eficiente para ser utilizado al extraer, almacenar y
manipular información de la base de datos. Todas
las peticiones de acceso a la base, se manejan
centralizadamente por medio del DBMS.Las bases de datos han evolucionado durante los pasados 30
años desde sistemas de archivos rudimentarios
hasta sistemas gestores de complejas estructuras de datos que
ofrecen un gran número de
posibilidades.
POTENCIALIDADES
Redundancia mÃnima
Acceso concurrente por parte de múltiples
usuariosDistribución espacial de los datos
OBJETIVOS DE LOS DBMS
Independencia lógica y fÃsica
de los datos: se refiere a la capacidad de modificar una
definición de esquema en un nivel de la arquitectura
sin que esta modificación afecte al nivel
inmediatamente superior. Para ello un registro
externo en un esquema externo no tiene por qué
ser igual a su registro correspondiente en el esquema
conceptual.Integridad de los datos: se refiere a las medidas
de seguridad que impiden que se introduzcan datos
erróneos. Esto puede suceder tanto por motivos
fÃsicos (defectos de hardware,
actualización incompleta debido a causas
externas), como de operación
(introducción de datos incoherentes).Consultas complejas optimizadas: la
optimización de consultas permite la
rápida ejecución de las
mismas.
SISTEMA ADMINISTRADOR DE BASES DE
DATOS
Seguridad de acceso y
auditorÃa: se refiere al derecho de acceso a
los datos contenidos en la base de datos por parte de
personas y organismos. El sistema de auditorÃa
mantiene el control de
acceso a la base de datos, con el objeto de saber
qué o quién realizó
una determinada modificación y en
qué momento.Respaldo y recuperación: se refiere
a la capacidad de un sistema de base de datos de recuperar su
estado en
un momento previo a la pérdida de datos.Acceso a través de lenguajes de
programación estándar: se
refiere a la posibilidad ya mencionada de acceder a los datos
de una base de datos mediante lenguajes de
programación basados en
estándares.
EL ROL DE LAS BASES DE DATOS Y LOS IS
Prácticamente todo Sistema de
Información esta sustentado por una Base de
Datos.La eficiencia e
integridad de un Sistema de Información se ve
directamente influenciado por el diseño de la
base de datos que lo sustenta y sus mecanismos de acceso.En el mundo informático empresarial existen
básicamente dos áreas de
especialización:
Desarrollo: el rol del
diseñador de Bases de DatosProducción: el rol del
Administrador de Base de Datos
Un DBMS tÃpico integra los siguientes
componentes:
Un lenguaje de definición de datos (DDL: Data
Definition Language).Un lenguaje de manipulación de datos (DML:
Data Manipulation Language)Un lenguaje de consulta (QL: Query Language).
De forma accesoria, pero ya casi obligada, los DBMS
modernos añaden un interfaz de usuario
gráfico (GUI: Graphical User Interface).
Existen numerosos DBMS comerciales, los principales
son:
Oracle (Oracle
Corp.)Sybase (Sybase Inc.)
SQL Server (Microsoft)
Informix (actualmente pertenece a IBM)
DB2 (IBM)
Postgres
Progress
MySQL
IMPORTANCIA DE LA MANIPULACIÓN
DE DATOS EN UNA BASE DE DATOS
La importancia de almacenar, manipular y recuperar la
información en forma eficiente ha llevado al
desarrollo de una teorÃa esencial para las bases de
datos. Esta teorÃa ayuda al diseño de
bases de datos y procesamiento eficiente de consultas por parte
de los usuarios.
Las arquitecturas de bases de datos han evolucionado mucho
desde sus comienzos, aunque la considerada estándar
hoy en dÃa es la descrita por el comité
ANSI/X3/SPARC (Standard Planning and Requirements Committee of
the American National Standards Institute on Computers and
Information Processing), que data de finales de los
años setenta.
Este comité propuso una arquitectura general para
DBMSs basada en tres niveles o esquemas: el nivel
fÃsico, o de máquina, el nivel externo,
o de usuario, y el nivel conceptual. Asà mismo
describió las interacciones entre estos tres niveles
y todos los elementos que conforman cada uno de ellos.
EL uso de las BD es contrario al enfoque tradicional, en que
cada sistema maneja sus propios datos y archivos. Al usar BD,
todos los datos se almacenan en forma integrada, y
están sujetos a un control centralizado. Las
diversas aplicaciones operan sobre este conjunto de datos.
ARQUITECTURA ANSI
OBJETIVOS
Hay tres caracterÃsticas importantes inherentes a
los sistemas de bases de datos: la separación entre
los programas de aplicación y los datos, el manejo
de múltiples vistas por parte de los usuarios y el
uso de un catálogo para almacenar el esquema de la
base de datos.
En 1975, el comité ANSI-SPARC (American National
Standard Institute – Standards Planning and Requirements
Committee) propuso una arquitectura de tres niveles para los
sistemas de bases de datos, que resulta muy útil a
la hora de conseguir estas tres caracterÃsticas.
Propiedad que asegura que los programas de
aplicación sean independientes de los cambios
realizados en datos que no usan o en detalles de
representación fÃsica de los datos a los
que acceden
ESTRUCTURA DE LA ARQUITECTURA ANSI
Grupo de estudio ANSI/SPARC en 1977 propuesta de arquitectura
para los DBMS que plantea la definición de la base
de datos a tres niveles de abstracción:
Nivel conceptual
Nivel interno
Nivel externo
Nivel conceptual
Representa la abstracción de "como la realidad
es".
Ejemplo:
Empleado (nombre, dirección,
teléfono, depto, sueldo)
Nivel interno
En el nivel interno se describe la estructura
fÃsica de la base de datos mediante un esquema
interno. Este esquema se especifica mediante un modelo
fÃsico y describe todos los detalles para el
almacenamiento de la base de datos, asà como los
métodos de acceso. Esquema interno:
descripción de la BD en términos de su
representación fÃsica.
Ejemplo:
·      Â
Archivo Empleados
Nombre : char [20]
Dirección : char [40]
Teléfono : char [10]
Depto : char [15]
Sueldo : REAL
·      Â
Archivo Ãndices por nombre
·      Â
Archivo Ãndices por depto
Nivel externo
En el nivel externo se describen varios esquemas
externos o vistas de usuario. Cada esquema externo
describe la parte de la base de datos que interesa a un grupo de
usuarios determinados y ocultos a ese grupo el resto de la base
de datos. En este nivel se puede utilizar un modelo conceptual o
un modelo lógico para especificar los esquemas.
Esquema externo: descripción de las vistas parciales
de la BD que poseen los distintos usuarios.
Ejemplo:
Subschema1: E1 (nombre, dirección,
teléfono)
Subschema2: E2 (nombre, depto, sueldo)

ENFOQUE DE BASES DE DATOS
En el enfoque de bases de datos se mantiene un
único almacén de datos que se
define una sola vez y al cual tienen acceso muchos
usuarios.Las principales ventajas del enfoque de Base de Datos
sobre el enfoque tradicional son:
Evita los datos repetidos (redundancia).
Evita que distintas copias de un dato tengan valores
distintos (inconsistencia).Evita que usuarios no autorizados accedan a los datos
(seguridad).Protege los datos contra valores no permitidos (integridad
o restricciones de consistencia).Permite que uno o más usuarios puedan
accesar simultáneamente a los datos
(concurrencia).
Instrucciones en SQL
El lenguaje de consulta estructurado (SQL) es un lenguaje de
base de datos normalizado, utilizado por el motor de base de
datos de Microsoft Jet. SQL se utiliza para crear objetos
QueryDef, como el argumento de origen del método
OpenRecordSet y como la propiedad
RecordSource del control de datos. También se puede
utilizar con el método Execute para crear y
manipular directamente las bases de datos Jet y crear consultas
SQL de paso a través para manipular bases de datos
remotas cliente – servidor.
Componentes del SQL
El lenguaje SQL está compuesto por comandos,
cláusulas, operadores y funciones de agregado.
Estos elementos se combinan en las instrucciones para crear,
actualizar y manipular las bases de datos.
Comandos
Existen dos tipos de comandos SQL: Â
los DLL que permiten crear y definir nuevas bases de
datos, campos e Ãndices.los DML que permiten generar consultas para ordenar,
filtrar y extraer datos de la base de datos.
Â
Comandos DLL | ||||||||
Comando | Descripción | |||||||
CREATE | Utilizado para crear nuevas tablas, campos e | |||||||
DROP | Empleado para eliminar tablas e Ãndices | |||||||
ALTER | Utilizado para modificar las tablas agregando campos o | |||||||
Comandos DML | ||||||||
Comando | Descripción | |||||||
SELECT | Utilizado para consultar registros | |||||||
INSERT | Utilizado para cargar lotes de datos en la base de datos | |||||||
UPDATE | Utilizado para modificar los | |||||||
DELETE | Utilizado para eliminar registros de una tabla de una | |||||||
Cláusulas
Las cláusulas son condiciones de
modificación utilizadas para definir los datos que
desea seleccionar o manipular. Â
Cláusula | Descripción | |||||
FROM | Utilizada para especificar la tabla de la cual se van a | |||||
WHERE | Utilizada para especificar las condiciones que deben | |||||
GROUP BY | Utilizada para separar los registros seleccionados en | |||||
HAVING | Utilizada para expresar la condición que | |||||
ORDER BY | Utilizada para ordenar los registros seleccionados de | |||||
Operadores Lógicos
Operador | Uso | |||||||
AND | Es el "y" lógico. Evalua dos condiciones y | |||||||
OR | Es el "o" lógico. Evalúa dos | |||||||
NOT | Negación lógica. Devuelve el | |||||||
Operadores de Comparación
Operador | Uso | |||
Mayor que | ||||
Distinto de | ||||
= | Mayor ó Igual que | |||
= | Igual que | |||
BETWEEN | Utilizado para especificar un intervalo de valores. | |||
LIKE | Utilizado en la comparación de un | |||
In | Utilizado para especificar registros de una base de | |||
Funciones de Agregado
Las funciones de agregado se usan dentro de una
cláusula SELECT en grupos de registros para
devolver un único valor que se aplica a un grupo de
registros. Â
Función | Descripción | |||||||
AVG | Utilizada para calcular el promedio de los valores de un | |||||||
COUNT | Utilizada para devolver el número de | |||||||
SUM | Utilizada para devolver la suma de todos los valores de | |||||||
MAX | Utilizada para devolver el valor más alto | |||||||
MIN | Utilizada para devolver el valor más bajo | |||||||
Consultas de Selección
Las consultas de selección se utilizan para
indicar al motor de datos que devuelva información
de las bases de datos, esta información es devuelta
en forma de conjunto de registros que se pueden almacenar en un
objeto recordset. Este conjunto de registros es modificable.
Consultas básicas
La sintaxis básica de una consulta de
selección es la siguiente:
SELECT Campos FROM Tabla;
En donde campos es la lista de campos que se deseen recuperar
y tabla es el origen de los mismos, por ejemplo:
SELECT Nombre, Telefono FROM Clientes;
Esta consulta devuelve un recordset con el campo
nombre y teléfono de la tabla clientes.
Ordenar los registros
Adicionalmente se puede especificar el orden en
que se desean recuperar los registros de las tablas mediante la
claúsula ORDER BY Lista de Campos. En donde Lista de
campos representa los campos a ordenar. Ejemplo:
SELECT CodigoPostal, Nombre, Telefono FROM
Clientes ORDER BY Nombre;
Esta consulta devuelve los campos CodigoPostal,
Nombre, Telefono de la tabla Clientes ordenados por el campo
Nombre.
Se pueden ordenar los registros por mas de un
campo, como por ejemplo:
SELECT CodigoPostal, Nombre, Telefono FROM
Clientes ORDER BY CodigoPostal, Nombre;
Incluso se puede especificar el orden de los
registros: ascendente mediante la claúsula (ASC -se
toma este valor por defecto) ó descendente
(DESC)
SELECT CodigoPostal, Nombre,
Teléfono FROM Clientes ORDER BY Codigo Postal
DESC , Nombre ASC;
Consultas con Predicado
El predicado se incluye entre la
claúsula y el primer nombre del campo a recuperar,
los posibles predicados son:
Predicado | Descripción | |||
ALL | Devuelve todos los campos de la tabla | |||
TOP | Devuelve un determinado número de registros | |||
DISTINCT | Omite los registros cuyos campos seleccionados coincidan | |||
DISTINCTROW | Omite los registros duplicados basándose | |||
ALL
Si no se incluye ninguno de los predicados se asume ALL. El
Motor de base de datos selecciona todos los
registros que cumplen las condiciones de la
instrucción SQL. No se conveniente abusar de este
predicado ya que obligamos al motor de la base de datos a
analizar la estructura de la tabla para averiguar los campos que
contiene, es mucho más rápido indicar
el listado de campos deseados.
SELECT ALL FROM Empleados;
SELECT * FROM Empleados;
TOP
Devuelve un cierto número de
registros que entran entre al principio o al final de un rango
especificado por una cláusula ORDER BY. Supongamos
que queremos recuperar los nombres de los 25 primeros estudiantes
del curso 1994:
SELECT TOP 25 Nombre, Apellido FROM Estudiantes
ORDER BY Nota DESC;
Si no se incluye la cláusula ORDER
BY, la consulta devolverá un conjunto arbitrario de
25 registros de la tabla Estudiantes .El predicado TOP no elige
entre valores iguales. En el ejemplo anterior, si la nota media
número 25 y la 26 son iguales, la consulta
devolverá 26 registros. Se puede utilizar la
palabra reservada PERCENT para devolver un cierto porcentaje de
registros que caen al principio o al final de un rango
especificado por la cláusula ORDER BY. Supongamos
que en lugar de los 25 primeros estudiantes deseamos el 10 por
ciento del curso:
SELECT TOP 10 PERCENT Nombre, Apellido FROM
Estudiantes ORDER BY Nota DESC;
El valor que va a continuación de TOP debe ser un
Integer sin signo.TOP no afecta a la posible
actualización de la consulta.
DISTINCT
Omite los registros que contienen datos duplicados en los
campos seleccionados. Para que los valores de cada campo listado
en la instrucción SELECT se incluyan en la consulta
deben ser únicos.
Por ejemplo, varios empleados listados en la tabla Empleados
pueden tener el mismo apellido. Si dos registros contienen
López en el campo Apellido, la siguiente
instrucción SQL devuelve un único
registro:
SELECT DISTINCT Apellido FROM Empleados;
Con otras palabras el predicado DISTINCT devuelve aquellos
registros cuyos campos indicados en la cláusula
SELECT posean un contenido diferente. El resultado de una
consulta que utiliza DISTINCT no es actualizable y no refleja los
cambios subsiguientes realizados por otros usuarios.
DISTINCTROW
Devuelve los registros diferentes de una tabla; a
diferencia del predicado anterior que sólo se fijaba
en el contenido de los campos seleccionados, éste lo
hace en el contenido del registro completo independientemente de
los campo indicados en la cláusula SELECT. SELECT
DISTINCTROW Apellido FROM Empleados;
Si la tabla empleados contiene dos registros:
Antonio López y Marta López el ejemplo
del predicado DISTINCT devuleve un único registro
con el valor López en el campo Apellido ya que busca
no duplicados en dicho campo. Este último ejemplo
devuelve dos registros con el valor López en el
apellido ya que se buscan no duplicados en el registro completo.
Alias
En determinadas circunstancias es necesario asignar un nombre
a alguna columna determinada de un conjunto devuelto, otras veces
por simple capricho o por otras circunstancias. Para resolver
todas ellas tenemos la palabra reservada AS que se encarga de
asignar el nombre que deseamos a la columna deseada. Tomado como
referencia el ejemplo anterior podemos hacer que la columna
devuelta por la consulta, en lugar de llamarse apellido (igual
que el campo devuelto) se llame Empleado. En este caso
procederÃamos de la siguiente forma:
SELECT DISTINCTROW Apellido AS Empleado FROM Empleados;
Recuperar Información de una base de Datos
Externa
Para concluir este capÃtulo se debe
hacer referencia a la recuperación de registros de
bases de datos externa. Es ocasiones es necesario la
recuperación de información que se
encuentra contenida en una tabla que no se encuentra en la base
de datos que ejecutará la consulta o que en ese
momento no se encuentra abierta, esta situación la
podemos salvar con la palabra reservada IN de la siguiente
forma:
SELECT DISTINCTROW Apellido AS Empleado FROM
Empleados IN 'c:databasesgestion.mdb';
En donde c:databasesgestion.mdb es la base de
datos que contiene la tabla Empleados.
Criterios de Selección
En el capÃtulo anterior se vio la
forma de recuperar los registros de las tablas, las formas
empleadas devolvÃan todos los registros de la
mencionada tabla. A lo largo de este capÃtulo se
estudiarán las posibilidades de filtrar los
registros con el fin de recuperar solamente aquellos que cumplan
una condición preestablecida.
Antes de comenzar el desarrollo de este capÃtulo
hay que recalcar tres detalles de vital importancia. El primero
de ellos es que cada vez que se desee establecer una
condición referida a un campo de texto la
condición de búsqueda debe ir encerrada
entre comillas simples; la segunda es que no se posible
establecer condiciones de búsqueda en los campos
memo y; la tercera y última hace referencia a las
fechas. Las fechas se deben escribir siempre en formato mm-dd-aa
en donde mm representa el mes, dd el dÃa y aa el
año, hay que prestar atención a los
separadores -no sirve la separación habitual de la
barra (/), hay que utilizar el guión (-) y
además la fecha debe ir encerrada entre
almohadillas (#). Por ejemplo si deseamos referirnos al
dÃa 3 de Septiembre de 1995 deberemos hacerlo de la
siguente forma; #09-03-95# ó #9-3-95#.
Operadores Lógicos
Los operadores lógicos soportados por SQL son:
AND, OR, XOR, Eqv, Imp, Is y Not. A excepción de los
dos últimos todos poseen la siguiente sintaxis:
expresión1  Â
operador  Â
expresión2
En donde expresión1 y
expresión2 son las condiciones a evaluar, el
resultado de la operación varÃa en
función del operador lógico. La tabla
adjunta muestra los
diferentes posibles resultados: Â Â
expresión1 | Operador | Resultado | |
Verdad | AND | Falso | Falso |
Verdad | AND | Verdad | Verdad |
Falso | AND | Verdad | Falso |
Falso | AND | Falso | Falso |
Verdad | OR | Falso | Verdad |
Verdad | OR | Verdad | Verdad |
Falso | OR | Verdad | Verdad |
Falso | OR | Falso | Falso |
Verdad | XOR | Verdad | Falso |
Verdad | XOR | Falso | Verdad |
Falso | XOR | Verdad | Verdad |
Falso | XOR | Falso | Falso |
Verdad | Eqv | Verdad | Verdad |
Verdad | Eqv | Falso | Falso |
Falso | Eqv | Verdad | Falso |
Falso | Eqv | Falso | Verdad |
Verdad | Imp | Verdad | Verdad |
Verdad | Imp | Falso | Falso |
Verdad | Imp | Null | Null |
Falso | Imp | Verdad | Verdad |
Falso | Imp | Falso | Verdad |
Falso | Imp | Null | Verdad |
Null | Imp | Verdad | Verdad |
Null | Imp | Falso | Null |
Null | Imp | Null | Null |
Si a cualquiera de las anteriores condiciones le anteponemos
el operador NOT el resultado de la operación
será el contrario al devuelto sin el operador
NOT.
El último operador denominado Is se
emplea para comparar dos variables de
tipo objeto Is . este operador devuelve verdad si los dos objetos
son iguales
SELECT * FROM Empleados WHERE Edad > 25 AND
Edad < 50; SELECT * FROM Empleados WHERE (Edad > 25 AND
Edad < 50) OR Sueldo = 100;
SELECT * FROM Empleados WHERE NOT Estado =
'Soltero'; SELECT * FROM Empleados WHERE (Sueldo > 100 AND
Sueldo < 500) OR Provincia = 'Madrid' AND Estado =
'Casado');
Intervalos de Valores
Para indicar que deseamos recuperar los registros
según el intervalo de valores de un campo
emplearemos el operador Between cuya sintaxis es: campo [Not]
Between valor1 And valor2 (la condición Not es
opcional)
En este caso la consulta devolverÃa
los registros que contengan en "campo" un valor incluido en el
intervalo valor1, valor2 (ambos inclusive). Si anteponemos la
condición Not devolverá aquellos
valores no incluidos en el intervalo.
SELECT * FROM Pedidos WHERE CodPostal Between
28000 And 28999; (Devuelve los pedidos realizados en la provincia
de Madrid)
SELECT IIf(CodPostal Between 28000 And 28999,
'Provincial', 'Nacional') FROM Editores; (Devuelve el valor
'Provincial' si el código postal se encuentra en el
intervalo, 'Nacional' en caso contrario)
El Operador Like
Se utiliza para comparar una expresión de cadena
con un modelo en una expresión SQL. Su sintaxis
es:
expresión Like modelo
En donde expresión es una cadena modelo o campo
contra el que se compara expresión. Se puede
utilizar el operador Like para encontrar valores en los campos
que coincidan con el modelo especificado. Por modelo puede
especificar un valor completo (Ana MarÃa), o se
pueden utilizar caracteres comodÃn como los
reconocidos por el sistema operativo
para encontrar un rango de valores (Like An*).
El operador Like se puede utilizar en una
expresión para comparar un valor de un campo con una
expresión de cadena. Por ejemplo, si introduce Like
C* en una consulta SQL, la consulta devuelve todos los valores de
campo que comiencen por la letra C. En una consulta con
parámetros, puede hacer que el usuario escriba el
modelo que se va a utilizar.
El ejemplo siguiente devuelve los datos que comienzan con la
letra P seguido de cualquier letra entre A y F y de tres
dÃgitos:
Like 'P[A-F]###'
Este ejemplo devuelve los campos cuyo contenido empiece con
una letra de la A a la D seguidas de cualquier cadena.
Like '[A-D]*'
En la tabla siguiente se muestra cómo utilizar el
operador Like para comprobar expresiones con diferentes modelos.
Tipo de coincidencia | Modelo Planteado | Coincide | No coincide | |
Varios caracteres | 'a*a' | 'aa', 'aBa', 'aBBBa' | 'aBC' | |
Carácter especial |  'a[*]a' | 'a*a' | 'aaa' | |
Varios caracteres | 'ab*' | 'abcdefg', 'abc' | 'cab', 'aab' | |
Un solo carácter | 'a?a' | 'aaa', 'a3a', 'aBa' | 'aBBBa' | |
Un solo dÃgito | 'a#a' | 'a0a', 'a1a', 'a2a' | 'aaa', 'a10a' | |
Rango de caracteres | '[a-z]' | 'f', 'p', 'j' | '2', '&' | |
Fuera de un rango | '[!a-z]' | '9', '&', '%' | 'b', 'a' | |
Distinto de un dÃgito | '[!0-9]' | 'A', 'a', '&', '~' | '0', '1', '9' | |
Combinada | 'a[!b-m]#' | 'An9', 'az0', 'a99' | 'abc', 'aj0' | |
Â
El Operador In
Este operador devuelve aquellos registros cuyo campo indicado
coincide con alguno de los en una lista. Su sintaxis es:
expresión [Not] In(valor1, valor2, . . .)
SELECT * FROM Pedidos WHERE Provincia In
('Madrid', 'Barcelona', 'Sevilla'); Â La
cláusula WHERE
La cláusula WHERE puede usarse para
determinar qué registros de las tablas enumeradas en
la cláusula FROM aparecerán en los
resultados de la instrucción SELECT.
Depués de escribir esta cláusula se
deben especificar las condiciones expuestas en los partados 3.1 y
3.2. Si no se emplea esta cláusula, la consulta
devolverá todas las filas de la tabla. WHERE es
opcional, pero cuando aparece debe ir a continuación
de FROM.
SELECT Apellidos, Salario FROM
Empleados WHERE Salario > 21000;
SELECT Id_Producto, Existencias FROM Productos
WHERE Existencias $1000000.00
AND AVG (OrderQty) < 3;
GO
Observe que cuando en HAVING se incluyen varias condiciones,
éstas se combinan mediante AND, OR o NOT.
Para ver los productos con ventas totales superiores a
2.000.000 de dólares, utilice la siguiente
consulta:
USE AdventureWorks;
GO
SELECT ProductID, Total = SUM(LineTotal)
FROM Sales.SalesOrderDetail
GROUP BY ProductID
HAVING SUM(LineTotal) > $2000000.00 ;
GO
ALTER TABLE | |
La sentencia ALTER TABLE sirve para modificar la También nos permite crear nuevas La sintaxis es la siguiente: | |
|

La sintaxis de restriccion1 es idéntica a |
|

La sintaxis de restriccion2 es idéntica a |
|

| |
Ejemplo: ALTER TABLE tab1 ADD COLUMN col3 integer NOT NULL Con este ejemplo estamos añadiendo a la Cuando añadimos una columna lo ALTER TABLE tab1 ADD col3 integer En este caso la nueva columna admite valores nulos y | |
| |
Ejemplo: ALTER TABLE tab1 ADD CONSTRAINT c1 UNIQUE (col3) Con este ejemplo estamos añadiendo a la |
| |
Ejemplo: ALTER TABLE tab1 DROP COLUMN col3 También podemos escribir: ALTER TABLE tab1 DROP col3 El resultado es el mismo, la columna col3 desaparece de | |
| |
Ejemplo: ALTER TABLE tab1 DROP CONSTRAINT c1 Con esta sentencia borramos el índice c1 creado | |
DROP TABLE | |
La sentencia DROP TABLE sirve para La sintaxis es la siguiente: | |
| |
Ejemplo: DROP TABLE tab1 Elimina de la base de datos la tabla tab1.
| |
CREATE INDEX | |
La sentencia CREATE INDEX sirve para La sintaxis es la siguiente: | |
| |
nbindi: nombre del nbtabla: nombre de la tabla donde definimos el nbcol: nombre de la columna que indexamos. ASC: la cláusula ASC es la que se DESC: indica orden descendente, es decir Podemos formar un índice basado en varias Opcionalmente se pueden indicar las WITH PRIMARY indica que el índice define WITH DISALLOW NULL indica que no permite WITH IGNORE NULL indica que las filas que
| |
Ejemplo: CREATE UNIQUE INDEX ind1 ON clientes Crea un índice llamado ind1 sobre la Al añadir la cláusula UNIQUE el CREATE INDEX ind1 ON clientes (provincia, poblacion
| |
DROP INDEX | |
La sentencia DROP INDEX sirve para La sintaxis es la siguiente: | |
| |
Ejemplo: DROP INDEX ind1 ON clientes Elimina el índice que habíamos creado en | |
 Para
Para


SUM (Transact-SQL)
Devuelve la suma de todos los valores o
sólo de los valores DISTINCT de la expresión. SUM
sólo puede utilizarse con columnas numéricas. Los
valores Null se pasan por alto. Puede ir seguida de la
cláusula OVER.
Convenciones de sintaxis de Transact-SQL
Sintaxis
SUM ( [ ALL | DISTINCT ] expression )
 Argumentos
Argumentos
ALL
Aplica la función de
agregado a todos los valores. ALL es el valor
predeterminado.
DISTINCT
Especifica que SUM devuelve la suma de los valores
únicos.
expression
Es una constante, columna o función y cualquier
combinación de operadores aritméticos, bit a bit y
de cadena. expression es una expresión de la
categoría del tipo de datos numérico exacto o
numérico aproximado, excepto para el tipo de datos
bit. No se permiten funciones de
agregado ni subconsultas.
Tipos de valor devueltos
Devuelve la suma de todos los valores de expression
con el tipo de datos expression más preciso.
Resultado de la expresión | Valor devuelto | |
Categoría integer | int | |
Categoría decimal (p, s) | decimal(38, s) | |
Categoría money y smallmoney | money | |
Categoría float y real | float | |
| ||
No se admiten agregados Distinct, por ejemplo AVG(DISTINCT | ||
Ejemplos
A. Utilizar SUM para agregados y agregados de
filas
En estos ejemplos se muestran las diferencias entre las
funciones de agregado y las funciones de agregado de filas. En el
primero se muestran funciones de agregado que sólo ofrecen
datos de resumen y en el segundo, funciones de agregado de filas
que ofrecen datos de resumen y de detalle.
USE AdventureWorks;
GO
SELECT Color,
SUM(ListPrice), SUM(StandardCost)
FROM Production.Product
WHERE Color IS NOT NULL AND ListPrice != 0.00 AND Name LIKE
'Mountain%'
GROUP BY Color
ORDER BY Color;
GO
USE AdventureWorks;
GO
SELECT Color, ListPrice, StandardCost
FROM Production.Product
WHERE Color IS NOT NULL AND ListPrice != 0.00 AND Name LIKE
'Mountain%'
ORDER BY Color
COMPUTE SUM(ListPrice), SUM(StandardCost) BY Color;
GO
COUNT (Transact-SQL)
Devuelve el número de elementos de un grupo. COUNT
funciona como COUNT_BIG. La única diferencia entre ambas
funciones está en los valores devueltos. COUNT siempre
devuelve un valor de tipo de datos int. COUNT_BIG siempre
devuelve un valor de tipo de datos bigint. Puede ir
seguida de la cláusula OVER.
Convenciones de sintaxis de Transact-SQL
Sintaxis
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
Argumentos
ALL
Aplica la función de agregado a todos los valores. ALL
es el valor predeterminado.
DISTINCT
Especifica que COUNT devuelva el número de valores
únicos no NULL.
expression
Es una expression de cualquier tipo excepto text,
image o ntext. No se permite utilizar funciones de
agregado ni subconsultas.
*
Especifica que se deben contar todas las filas para devolver
el número total de filas de una tabla. COUNT(*) no acepta
parámetros y no se puede utilizar con DISTINCT. COUNT(*)
no requiere un parámetro expression porque, por
definición, no utiliza información sobre ninguna columna
específica. COUNT(*) devuelve el número de filas de
una tabla especificada sin deshacerse de las duplicadas. Cuenta
cada fila por separado. Se incluyen las filas que contienen
valores NULL.
|
No se admiten agregados Distinct, por ejemplo |
 Importante:
Importante:Tipos de valor devueltos
int
Notas
COUNT (*) devuelve el número de elementos de un grupo.
Se incluyen valores NULL y duplicados.
COUNT (ALL expression) evalúa
expression en todas las filas del grupo y devuelve el
número de valores no NULL.
COUNT (DISTINCT expression) evalúa
expression en todas las filas del grupo y devuelve el
número de valores no NULL únicos.
Si los valores devueltos son superiores a 2^31-1, COUNT genera
un error. En su lugar, utilice COUNT_BIG.
Ejemplos
A. Usar COUNT y DISTINCT
En el ejemplo siguiente se muestra el
número de cargos diferentes que puede tener un empleado
que trabaja en Adventure Works Cycles.
USE AdventureWorks;
GO
SELECT COUNT(DISTINCT Title)
FROM HumanResources.Employee;
GO
B. Usar COUNT (*)
USE AdventureWorks;
GO
SELECT COUNT(*)
FROM HumanResources.Employee;
GO
C. Usar COUNT (*) con otros agregados
USE AdventureWorks;
GO
SELECT COUNT (*), AVG (Bonus)
FROM Sales.SalesPerson
WHERE SalesQuota > 25000;
GO
AVG (Transact-SQL)
Devuelve el promedio de los valores de un grupo. Los valores
NULL se pasan por alto. Puede ir seguida de la cláusula
OVER.
Convenciones de sintaxis de Transact-SQL
Sintaxis
AVG ([ALL | DISTINCT] expression)
Argumentos
ALL
Aplica la función de agregado a todos los valores. ALL
es el valor predeterminado.
DISTINCT
Especifica que AVG se ejecute sólo en cada instancia
única de un valor, sin importar el número de veces
que aparezca el valor.
expression
Es una expresión de la categoría de tipo de
datos numérico exacto o numérico aproximado,
excepto para el tipo de datos bit. No se permite utilizar
funciones de agregado ni subconsultas.
Tipos de valor devueltos
El tipo de valor devuelto viene determinado por el tipo del
resultado evaluado de expression.
Resultado de la expresión | Tipo de valor devuelto |
Categoría integer | int |
Categoría decimal (p, s) | decimal(38, s) dividido por decimal(10, |
Categoría money y smallmoney | money |
Categoría float y real | float |
Notas
Si el tipo de datos de expression es un tipo de datos
de alias, el tipo de valor devuelto es también del tipo de
datos de alias. No obstante, si se asciende el tipo de datos base
del tipo de datos de alias, por ejemplo, de tinyint a
int, el valor devuelto es del tipo de datos ascendido, no
del tipo de datos de alias.
Ejemplos
A. Utilizar las funciones SUM y AVG para los
cálculos
En el ejemplo siguiente se calcula el promedio de horas de
vacaciones y la suma de horas de baja por enfermedad que han
utilizado los vicepresidentes de Adventure Works Cycles. Cada una
de estas funciones de agregado produce un valor único de
resumen para todas las filas recuperadas.
USE AdventureWorks;
GO
SELECT AVG(VacationHours)as 'Average vacation hours',
SUM (SickLeaveHours) as 'Total sick leave hours'
FROM HumanResources.Employee
WHERE Title LIKE 'Vice President%';
B. Utilizar las funciones SUM y AVG con una
cláusula GROUP BY
Cuando se utiliza con una cláusula GROUP BY, cada
función de agregado produce un solo valor para cada grupo,
en vez de para toda la tabla. En el ejemplo siguiente se obtienen
valores de resumen para cada territorio de ventas. El
resumen muestra el promedio de bonificaciones recibidas por los
vendedores de cada territorio y la suma de las ventas realizadas
hasta la fecha en cada territorio.
USE AdventureWorks;
GO
SELECT TerritoryID, AVG(Bonus)as 'Average bonus',
SUM(SalesYTD) 'YTD sales'
FROM Sales.SalesPerson
GROUP BY TerritoryID;
GO
C. Utilizar AVG con DISTINCT
En la instrucción siguiente se devuelve el precio de
venta promedio de
los productos.
USE AdventureWorks;
GO
SELECT AVG(DISTINCT ListPrice)
FROM Production.Product;
D. Utilizar AVG sin DISTINCT
Sin DISTINCT, la función AVG busca el precio de venta
promedio de todos los productos de la tabla Product.
 Copiar
Copiar
código
USE AdventureWorks;
GO
SELECT AVG(ListPrice)
FROM Production.Product;
MAX (Transact-SQL)
Devuelve el valor máximo de la expresión. Puede
ir seguida de la cláusula OVER.
Convenciones de sintaxis de Transact-SQL
Sintaxis
MAX ( [ ALL | DISTINCT ] expression )
Argumentos
ALL
Aplica la función de agregado a todos los valores. ALL
es el valor predeterminado.
DISTINCT
Especifica que se tiene en cuenta cada valor único.
DISTINCT no tiene ningún significado con MAX y sólo
se incluye para la compatibilidad con SQL-92.
expression
Se trata de una constante, nombre de columna o función
y cualquier combinación de operadores aritméticos,
bit a bit y de cadena. MAX se puede usar con columnas
numéricas, de caracteres y de datetime, pero no con
columnas de bit. No se permiten funciones de agregado ni
subconsultas.
Tipos de valor devueltos
Notas
MAX pasa por alto los valores NULL.
Para las columnas de caracteres, MAX busca el valor más
alto de la secuencia de intercalación.
Ejemplos
En el siguiente ejemplo se devuelve el tipo impositivo mayor
(máximo).
USE AdventureWorks;
GO
SELECT MAX (TaxRate)
FROM Sales.SalesTaxRate;
GO
MIN (Transact-SQL)
Devuelve el valor mínimo de la expresión. Puede
ir seguida de la cláusula OVER.
Convenciones de sintaxis de Transact-SQL
Sintaxis
MIN ( [ ALL | DISTINCT ] expression )
Argumentos
ALL
Aplica la función de agregado a todos los valores. ALL
es el valor predeterminado.
DISTINCT
Especifica que se tiene en cuenta cada valor único.
DISTINCT no tiene ningún significado con MIN y está
disponible sólo por compatibilidad con SQL-92.
expression
Se trata de una constante, nombre de columna o función,
y cualquier combinación de operadores aritméticos,
bit a bit y de cadena. MIN se puede utilizar con columnas de tipo
numérico, char, varchar o datetime,
pero no con columnas de tipo bit. No se permite utilizar
funciones de agregado ni subconsultas.
Tipos de valor devueltos
Devuelve un valor igual a expression.
MIN pasa por alto los valores NULL.
En el caso de columnas de datos de caracteres, MIN busca el
valor más bajo en la secuencia de ordenación.
Ejemplos
En el ejemplo siguiente se devuelve la tasa de impuestos
más baja (mínima).
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |